

Three years ago, the technology world was abuzz with talk of artificial intelligence that could match human expertise. Today, that optimism has given way to a more sobering reality: even the most sophisticated AI systems routinely fabricate information, and the problem shows no sign of disappearing.
Despite billions in investment and steady technical progress, large language models (LLMs) continue to "hallucinate"—generating plausible-sounding but false information. New research suggests this is not merely a temporary hurdle but a fundamental limitation that affects even basic applications like document summarization.
Data from Vectara's hallucination leaderboard tells a mixed story. The best open-source models now achieve single-digit hallucination rates, a marked improvement from earlier systems. Yet the overall picture reveals troubling plateaus. Newer models do not automatically outperform their predecessors, and significant variation persists even among models of similar size and training approaches.
More concerning still, the trajectory suggests no inexorable march toward hallucination-free AI. Instead, progress appears to be levelling off—a pattern that mirrors other areas of AI development where initial rapid gains have slowed.
Nowhere are the consequences more stark than in legal AI, where accuracy is paramount and mistakes carry real-world costs. A recent Stanford study examined three leading legal research tools—products by LexisNexis, Thomson Reuters, and Westlaw that specifically market themselves as reliable alternatives to general-purpose chatbots.
The results were sobering. Even these specialized systems, built with curated legal databases and sophisticated retrieval mechanisms, hallucinated between 17% and 33% of the time. They fabricated non-existent legal provisions, mischaracterized court holdings, and confused jurisdictional hierarchies—precisely the kinds of errors that could derail legal cases.
The study's authors found instances where AI systems claimed that bankruptcy rules contained provisions they did not, or asserted that lower courts had overruled Supreme Court decisions—a legal impossibility. These were not subtle interpretive differences but fundamental factual errors.
Another dimension of the problem emerges from research examining real-world user queries. Stanford's "WildHallucinations" study analyzed entities that people actually ask AI systems about, drawn from genuine user conversations.
The findings reveal a crucial blind spot: 52% of the entities users inquire about lack Wikipedia pages. This matters because most AI training and evaluation focuses heavily on Wikipedia-style knowledge. When systems venture beyond this well-documented territory—into niche companies, local organizations, or recent developments—hallucination rates spike noticeably.
The study found particularly high error rates in finance and biographical information, precisely the domains where users often seek current, specific details that may not appear in traditional reference sources.
Industry observers had pinned considerable hope on retrieval-augmented generation (RAG)—systems that ground their responses in retrieved documents rather than relying solely on training data. The logic seemed sound: if models could access relevant information before generating responses, surely accuracy would improve dramatically.
Reality has proven more complex. While RAG systems do show some improvement over their base models, they fall far short of industry claims about "eliminating" hallucinations. The Stanford legal study found that even with access to comprehensive legal databases, RAG-powered tools continued to fabricate information at troubling rates.
Some retrieval-augmented models performed worse than their base versions. Analysis revealed that 43.7% of errors in advanced RAG systems stemmed from generation failures—cases where the system had access to correct information but failed to use it appropriately.
Perhaps most troubling is evidence from Vectara's evaluation framework that hallucinations affect even the most basic AI applications. Document summarization—ostensibly a straightforward task of condensing provided information—proves vulnerable to the same fabrication tendencies that plague complex reasoning tasks. Vectara's methodology tests exactly this scenario: whether models can accurately summarize a set of facts without adding unsupported details.
The persistent hallucination rates across their leaderboard, even for this fundamental task, reveal how deeply the problem runs. When models cannot reliably summarize provided information without fabricating additional content, it suggests that no AI application, however simple, is immune to these failures.
I made a visualisation using the Vectara data:
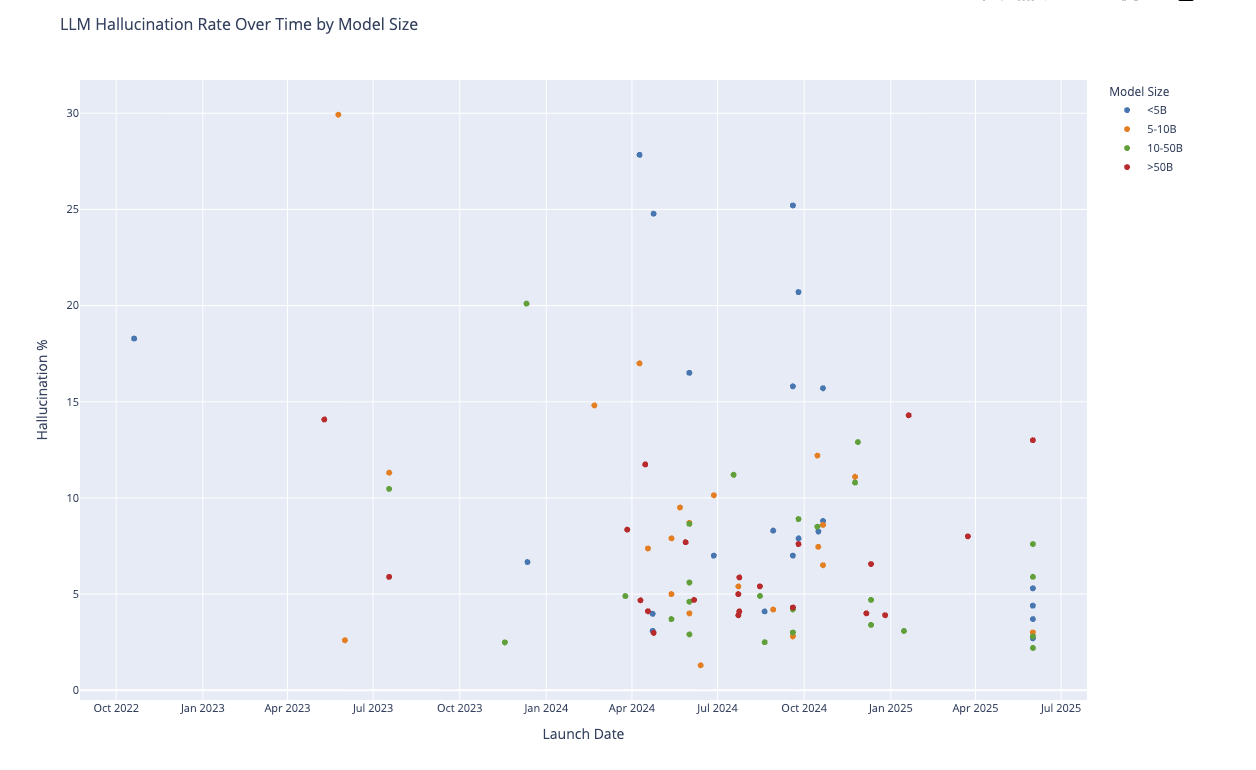
You can play with an interactive version here. This chart shows open source models on the Vectara benchmark. The chart shows that there is a huge range in hallucination rate even between the very largest model (and between the very newest models). I’ve only included open-source models in the graph (to allow comparison of parameter counts) but commercial models are not immune to the problem: OpenAI GPT-4.1 has a 2% hallucination rate, for example.
The evidence points to an uncomfortable truth: two and a half years after the release of ChatGPT, hallucinations still represent a severe and persistent limitation of current AI models. They affect not just experimental systems but commercial products specifically designed for high-stakes applications. They persist despite sophisticated engineering efforts. And they occur across the spectrum of AI tasks, from complex analysis to simple summarization.
This is not to diminish the genuine progress that has been made. The best systems today are measurably more reliable than their predecessors. Specialized tools do outperform general-purpose alternatives. Detection methods have grown more sophisticated, helping identify problematic outputs.
But as organizations rush to deploy AI in critical applications, they must reckon with a fundamental reality: the technology remains prone to fabrication in ways that may prove intractable.
The hallucination problem, it seems, will be with us for some time yet.
Author: Martin Goodson
Martin is a former Oxford University scientific researcher and has led AI research at several organisations. In 2019, he was elected Chair of the Data Science and AI Section of the Royal Statistical Society, the membership group representing professional data scientists in the UK. Martin is the CEO of the multiple award-winning data extraction firm Evolution AI. He also leads the London Machine Learning Meetup, the largest AI & machine learning community in Europe.



